How to use fastai's mid-level API
Now I can train models on Kaggle data sets!




In the previous blog where I trained a model to predict movie review sentiments, I created my DataLoaders by using a TextBlock. The fastai library is built on a layered API where the top layer has applications; we used the high level API (the DataBlock API).
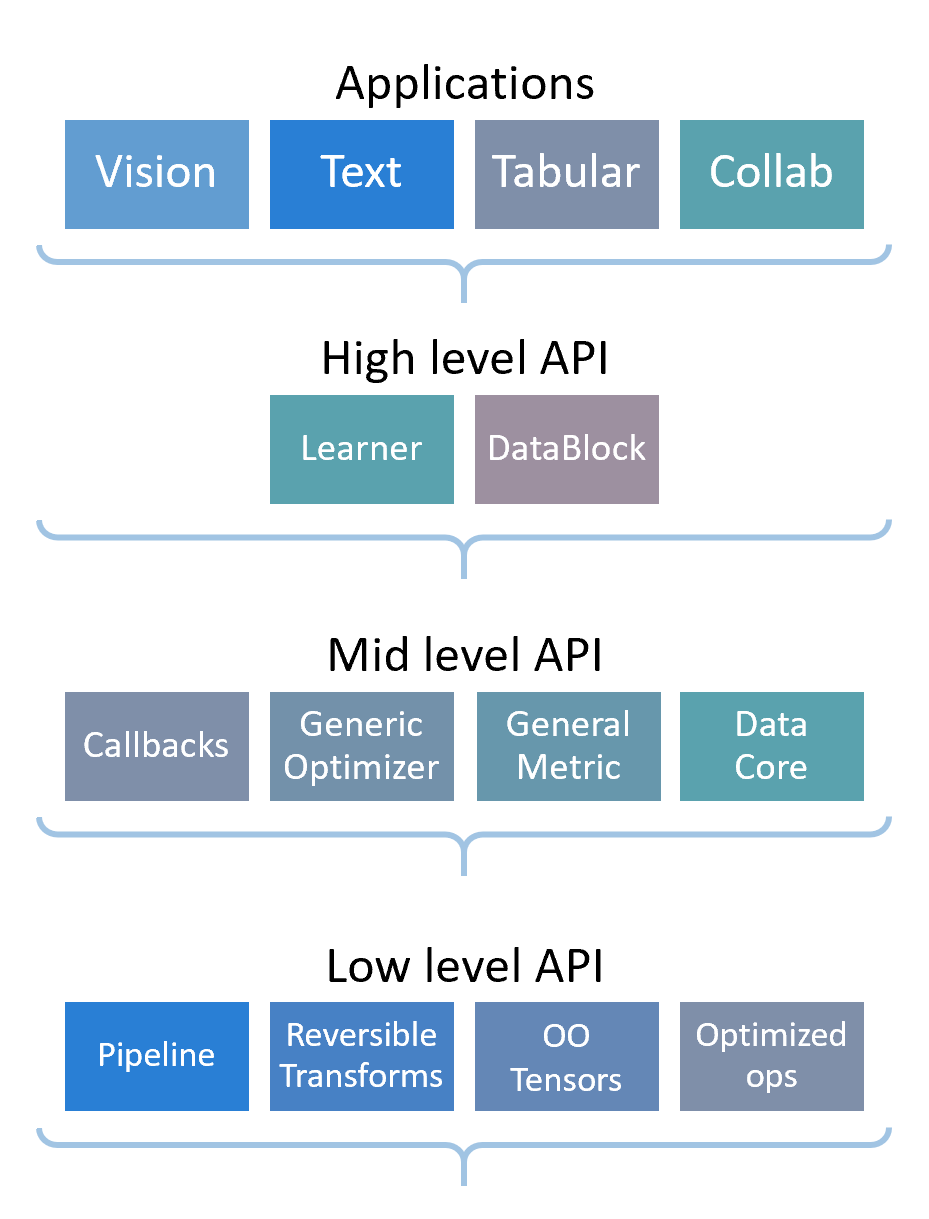
At a lower level, TextBlock applies both Tokenize and Numericalize, which tokenize, then numericalize the raw input text. Both classes inherit from the Transform class.
An instance of a Transform class is an object that has
- an
encodesmethod that can be called by(), allowing the object to be used like a function, - an optional
setupmethod to initialize some inner state, and - an optional
decodemethod to reverse the function (which may or may not be fully reversible; the importance is that it makes it easier for humans to read).
A Transform can work on a tuple. Transforms usually have their inputs specified with types so only items in the tuple with the correct type have the Transform applied.
In writing your own Transform, you can either decorate a function with @Transform or inherit from Transform, where:
| To call | To implement |
|---|---|
| () | encodes |
| setup() | setups |
| decode() | decodes |
You have to implement them in a different name since Transform does some things before calling setups and decodes in setup() and decode().
So with a decorator, we have:
@Transform
def f(x: int):
return x + 1
When you define a function with the @Transform decorator, you can only define the encodes part.
f((2, 2.0, '2')), f(2), f((2.0,)), f([2])
We can apply the Transform to a tuple (and since we defined it for ints it only applies to 2 and not 2.0 or '2'), a single element, a single element tuple, or a list.
If we wanted to implement setup() and decode(), we'll have to subclass Transform:
class Normalize_(Transform):
def setups(self, items, pop=False):
self.mean = sum(items) / len(items)
self.std = sum([(i - self.mean)**2 for i in items]) / (len(items) - (0 if pop else 1))
def encodes(self, x):
return (x - self.mean) / self.std
def decodes(self, x):
return x * self.std + self.mean
Then, we'll instantiate it and call setup with our items:
xs = [0, 1, 2, 3, 4, 5, 6]
n = Normalize_()
n.setup(xs)
n.mean, n.std
And finally, we'll test it:
x = (3, 3 + n.std)
x_encoded = n(x)
x_decoded = n.decode(x_encoded)
x, x_encoded, x_decoded
Typically, you want to use multiple Transforms on your raw items. There's 3 main ways to do that with fastai:
Pipelines,TfmdListss, andDatasetss.
Each have their own uses and differences (and there's a reason why some of end with an s).
Starting with Pipelines, you pass it a list of instantiated Transforms:
# Add 1 to each item, then normalize them
p = Pipeline([f, n])
p((2, 3))
If we want to pass in a list of Transform classes or functions, we need to use TfmdLists instead:
# Add 1 to each item, then use those values to setup Normalize
# (now the values are centered at 4 instead of 3)
tl = TfmdLists(xs, [f, Normalize])
tl((2, 3, 4))
With TfmdLists, we provide the raw items needed for the setup of each Transform and a list of the Transforms we want to use. At initialization, TfmdLists calls the setup() of each Transform, but it passes the raw items transformed by all previous Transforms in order instead of the raw items.
TfmdLists ends with an s since it can handle splits for training and validation sets. To split the data, you have to specify a split:
tls = TfmdLists(xs, [f, Normalize], splits=RandomSplitter()(xs))
tls.mean, tls.std, tls.train.items, tls.valid.items
You should be careful though because the setup of the Transforms will be done with the raw items in the train set instead of the entire set.
Finally with Datasets, you can think of it as multiple TfmsLists put together in a tuple, where each item produced by a Datasets is (tls1, tls2, ...). In general, we'll have two parallel pipelines of Transforms: (1) to process raw items into inputs and (2) to process raw items into targets. But, you can also have as many parallel pipelines as you want (for example, if you have multiple inputs and/or multiple targets; that's why there's the ... in (tls1, tls2, ...)).
So, for a Datasets, it could look like this:
class better_f(Transform):
def encodes(self, x):
return x + 1
def decodes(self, x):
return x - 1
x_tfms = [better_f, Normalize]
y_tfms = [] # a pipeline can also be empty
z_tfms = [Identity] # if empty is boring, you can also use Identity
dsets = Datasets(xs, [x_tfms, y_tfms, z_tfms], splits=RandomSplitter()(xs))
dsets, dsets.train, dsets.valid
And since we redefined f as a subclass of Transform with a decode method, we can get our raw items by decoding them:
[dsets.decode(dsets[i]) for i in range(len(xs))]
Lastly, we can create DataLoaders from a Dataset using the dataloaders attribute:
dls = dsets.dataloaders(bs=2)
dls.train.one_batch(), dls.valid.one_batch()
dataloaders works by calling DataLoader on each subset of our Datasets (like train and valid) and then putting them together into a DataLoaders.
The dataloaders has a few important parameters that are equivalent to the ones we use in DataBlocks:
after_itemtakesTransforms and applies them on each item after grabbing them from the dataset (equivalent toitem_tfmsinDataBlock).before_batchis applied to each item in a batch before they're collated.after_batchis applied on the batch after collation (equivalent tobatch_tfmsinDataBlock).
When would you want to use before_batch? When you want to apply something to each item in a batch instead of on the entire batch like in after_batch. For example, padding the documents for text so that all the items in the batch are of the same token length.
You can also specify the type of DataLoader you want. In NLP, you might want to use SortedDL through dsets.dataloaders(dl_type=SortedDL) which batches items of roughly the same length by sorting them beforehand.
Finally, when we call show_batch or show_results on a DataLoaders (or show on a TfmdLists or a Datasets), it continues to decode items until it reaches a type that has a show method. If there's no types with show (like Tensors), we get an error:
dls.show_batch()
To fix this error, you'll have to define (or use) a custom type with a show method that can accept a ctx as a keyword argument (which could be a matplotlib axis for images or a row of a DataFrame for texts).
Then, you need to include a Transform in the pipeline that converts your inputs into that custom type and ideally is the first Transform in the pipeline so that when you call show, it decodes all the way to the raw items.
In this blog, I covered the lower-level parts of the fastai library: Transforms and how to use them through Pipelines, TfmdListss, and Datasetss. In the real world, the higher-level DataBlock API might not be flexible enough. So, you'll have to use the more flexible lower-level APIs that let you define your own Transforms, data types, and DataLoaders.